This article was first published on SearchServerVirtualization.TechTarget.com.
It’s a pretty big challenge to support dozens or hundreds of separate virtual machines. Add in the requirement for backups – something that generally goes without saying – and you have to figure out how to protect important information. Yes, that usually means at least two copies of each of these storage hogs. I understand that you’re not made of storage (unless, of course, you’re the disk array that’s reading this article on the web server). So what should you do? In this tip, I’ll outline several approaches to performing backups for VMs, focusing on the strengths and limitations of each.
Determining Backup Requirements
Let’s start by considering the requirements for performing backups. The list of gaols is pretty simple, in theory:
- Minimize data loss
- Minimize recovery time
- Simplify implementation and administration
- Minimize costs and resource usage
Unfortunately, some of these objectives are often at odds with each other. Since implementing any solution takes time and effort, start by characterizing the requirements for each of your virtual machines and the applications and services they support. Be sure to write in pencil, as it’s likely that you’ll be revising these requirements. Next, let’s take a look at the different options for meeting these goals.
Application-Level Backups
The first option to consider for performing backups is that of using application features to do the job. There’s usually nothing virtualization-specific about this approach. Examples include:
- Relational Database Servers: Databases were designed to be highly-available and it should come as no surprise that there are many ways of using built-in backup methods. In addition to standard backup and restore operations, you can use replication, log-shipping, clustering, and other methods to ensure that data remains protected.
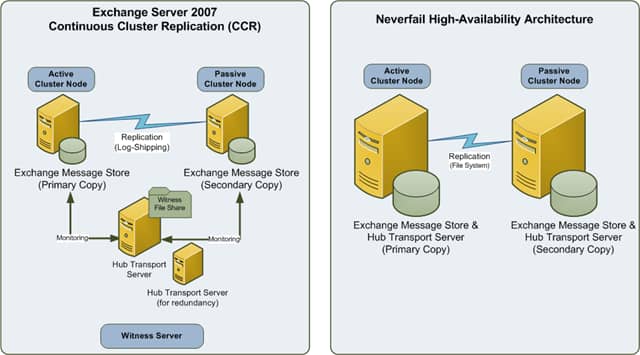
- Messaging Servers: Communications platforms such as Microsoft Exchange Server provide methods for keeping multiple copies of the data store in sync. Apart from improving performance (by placing data closer to those who need it), this can provide adequate backup functionality.
- Web Servers: The important content for a web server can be stored in a shared location or can be copied to each node in a web server farm. When a web server fails, just restore the important data to a standby VM, and you’re ready to go. Better yet, use shared session state or stateless application features and a network load-balancer to increase availability and performance.
All of these methods allow you to protect against data loss and downtime by storing multiple copies of important information.
Guest-Level Backups
What’s so special about VMs, anyway? I mean, why not just treat them like the physical machines that they think they are? That’s exactly the approach with guest-level backups. The most common method with this approach is to install backup agents within the guest OS and to specify which files should be backed up and their destinations. As with physical servers, administrators can decide what really needs to be backed up – generally just data, applications, and configuration files. That saves precious disk space and can reduce backup times.
There are, however, drawbacks to this backup approach. First, your enterprise backup solution must support your guest OS’s (try finding an agent for OS/2!) Assuming the guest OS is supported, the backup and recovery process is often different for each OS. This means more work on the restore side of things. Finally, the restore process can take significant time, since a base OS must be installed and the associated components restored.
Examples of popular enterprise storage and backup solutions are those from Symantec, EMC, Microsoft and many other vendors.
Host-Level Backups
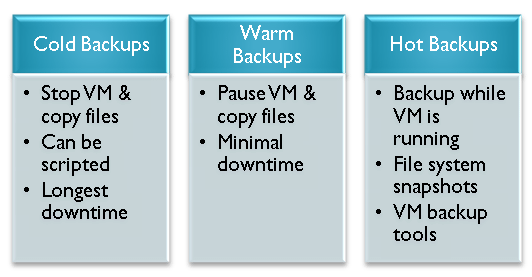
Host-level backups take advantage of the fact that virtual machines are encapsulated in one or more virtual disk files, along with associated configuration files. The backup process consists of making a copy of the necessary files from the host OS’s file system. Host-level backups provide a consistent method for copying VMs since you don’t have to worry about differences in guest operating systems. When it comes time to restore a VM (and you know it’s going to happen!), all that’s usually needed is to reattach the VM to a working host server.
However, the drawback is that you’re likely to need a lot of disk space. Since the entire VM, including the operating system, applications, and other data are included in the backup set, you’ll have to allocate the necessary storage resources. And, you’ll need adequate bandwidth to get the backups to their destination. Since virtual disk files are exclusively locked while a VM is running, you’ll either need to use a “hot backup” solution, or you’ll have to pause or stop the VM to perform a backup. The latter option results in (gulp!) scheduled downtime.
Solutions and technologies include:
- VMware: VMotion; High Availability; Consolidated Backup; DRS
- Microsoft Volume Shadow Services (VSS)
File System Backups
File system backups are based on features available in storage arrays and specialized software products. While they’re not virtualization-specific, they can help simplify the process of creating and maintaining VM backups. Snapshot features can allow you make a duplicate of a running VM, but you should make sure that your virtualization platform is specifically supported. File system replication features can use block- or bit-level features to keep a primary and backup copy of virtual hard disk files in-sync.
Since changes are transferred efficiently, less bandwidth is required. And, the latency between when modifications are committed on the primary VM and the backup VM can be minimized (or even eliminated). That makes the storage-based approach useful for maintaining disaster recovery sites. While third-party products are required, file system backups can be easy to setup and maintain. But, they’re not always ideal for write-intensive applications and workloads.
Potential solutions include products from Double-Take Software and from Neverfail. Also, if you’re considering the purchase of a storage solution, ask your vendor about replication and snapshot capabilities, and their compatibility with virtualization.
Back[up] to the Future
Most organizations will likely choose different backup approaches for different applications. For example, application-level backups are appropriate for those systems that support them. File system replication is important for maintaining hot or warm standby sites and services. Guest- and host-level backups balance ease of backup/restore operations vs. the amount of usable disk space. Overall, you should compile the data loss, downtime and cost constraints, and then select the most appropriate method for each type of VM. While there’s usually no single answer that is likely to meet all of your needs, there are some pretty good options out there!
 I recently had the opportunity to write several articles for Dell’s Tech Page One blog. I always enjoy thinking (and writing/speaking) about topics related to IT architecture changes. Over the last several years, that has focused on virtualization technology and cloud computer. A special
I recently had the opportunity to write several articles for Dell’s Tech Page One blog. I always enjoy thinking (and writing/speaking) about topics related to IT architecture changes. Over the last several years, that has focused on virtualization technology and cloud computer. A special