This article was first published on SearchServerVirtualization.TechTarget.com.
One of the many benefits of virtualization technology is its ability to de-couple workloads and operating systems from the underlying hardware on which they’re running. The end result is portability – the ability to move a VM between different physical servers without having to worry about minor configuration inconsistencies. This ability can greatly simplify a common IT challenge: Maintaining a disaster recovery site.
In an earlier article, “Implementing Backups for Virtual Machines”, I focused on performing backups from within guest OS’s. In this article, I’ll look at the other approach: Performing VM backups from within the host OS.
Determining What to Back Up
From a logical standpoint, virtual machines themselves are self-contained units that include a virtual hardware configuration, an operating system, applications, and services. Physically, however, there are numerous files and settings that must be transferred to a backup or disaster recovery site. While the details will differ based on the virtualization platform, the general types of files that should be considered include:
- Host server configuration data
- Virtual hard disks
- VM configuration files
- Virtual network configuration files
- Saved-state files
In some cases, thorough documentation and configuration management practices can replace the need to track some of the configuration data. Usually, all of the files except for the virtual hard disks are very small and can be transferred easily.
Performing Host-Level Backups
The primary issue related to performing VM backups is the fact that VHD files are constantly in use while the VM is running. While it might be possible to make a copy of a VHD while it is running, there’s a good chance that caching and other factors might make the copy unusable. This means that “open file agents” and snapshot-based backups need to be aware of virtualization in order to generate reliable (and restorable) backups.
There are three main ways in which you can perform host-level backups of VM-related files. Figure 1 provides an overview of these options. Cold backups are reliable and easy to implement, but they do require downtime. They’re suitable for systems that may be unavailable for at least the amount of time that it takes to make a copy of the associated virtual hard disk files. Hot Backups, on the other hand, can be performed while a VM is running. Virtualization-aware tools are usually required to implement this type of backup.
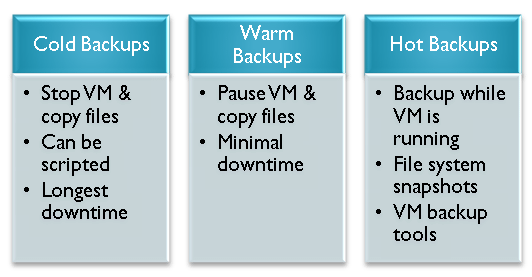
Figure 1: Options for performing host-level VM backups
Backup Storage Options
One of the potential issues with performing backups of entire virtual hard disks is the total amount of disk space that will be required. IT organizations have several different storage-related options. They are:
- Direct-Attached Storage (Host File System): This method involves storing copies of VHD files directly on the host computer. While the process can be quick and easy to implement, it doesn’t protect against the failure of the host computer or the host disk subsystem.
- Network-based Storage: Perhaps the most common destination for VM backups is network-based storage. Data can be stored on devices ranging from standard file servers, to dedicated network-attached storage (NAS) devices to iSCSI-based storage servers. Regardless of the technical details, bandwidth is an important concern. This is especially true when dealing with remote disaster recovery sites.
- Storage Area Networks (SANs): Organizations can use SAN-based connections to centrally manage storage, while still providing high performance for backups and related processes. SAN hardware is usually most applicable to backups performed within each of the disaster recovery sites, since there are practical limitations on the length of these connections.
Maintaining the Disaster Recovery Site
So far, we’ve looked at what you need to backup and some available storage technologies. The most important question, however, is that of how to maintain the disaster recovery site. Given that bandwidth and hardware may be limited, there are usually trade-offs. The first consideration is related to keeping up-to-date copies of VHDs and other files at both sites. While there are no magical solutions to this problem, many storage vendors provide for bit-level or block-level replication that can synchronize only the differences in large binary files. While there is usually some latency, this can minimize the bandwidth load while keeping files at both sites current.
At the disaster recovery site, IT staff will need to determine the level of capacity that must be reserved for managing failures situations. For example, will the server already be under load? If so, during a fail-over, what are the performance requirements? The process of performing a fail-over can be simplified through the use of scripts and automation. However, it’s critically important to test (and rehearse) the entire process before a disaster occurs.
Planning for the Worst…
Overall, the task of designing and implementing a disaster recovery configuration can be challenging. The use of virtual machines can simplify the process by loosening the requirements for identical hardware at the primary and backup sites. The process still isn’t easy, but with proper planning and the right tools, it’s certainly possible. Good luck, and let’s hope you never need to use your DR handiwork!

